
As enterprises adopt AI across business functions, attention naturally turns to how AI systems are built and operated over time. Early initiatives often begin with experimentation, but as usage expands, leaders start thinking more deliberately about data ownership, model flexibility, and how AI fits into existing enterprise systems. At this stage, the structure of the AI pipeline becomes as important as the intelligence it delivers.
This is where private AI pipelines come into focus. By designing pipelines that run on enterprise-owned data and support a choice of models, organizations can align AI initiatives with long-term architectural and governance goals. In this blog, we explore what private AI pipelines are, why enterprises are adopting them, and how GenE enables organizations to build production-ready AI pipelines that are designed to integrate cleanly with enterprise systems and evolve over time.
What Private AI pipelines Are and Why Enterprises Need Them
Private AI pipelines refer to AI pipelines that are designed to run within an enterprise’s own architectural and governance boundaries. These pipelines ingest enterprise data, apply selected AI models, and deliver outcomes through controlled execution paths that align with internal systems and policies. Instead of treating AI as an external capability, this approach positions AI as an integral part of the enterprise technology stack.
Enterprises adopt private AI pipelines to maintain clarity around data usage, model choice, and operational control as AI initiatives expand. This structure supports objectives such as data sovereignty, enterprise AI control, and the ability to build proprietary data workflows that reflect how the organization actually operates. As AI begins to support multiple teams and workflows, a defined private AI architecture helps ensure consistency and long-term alignment.
Key characteristics of private AI pipelines include:
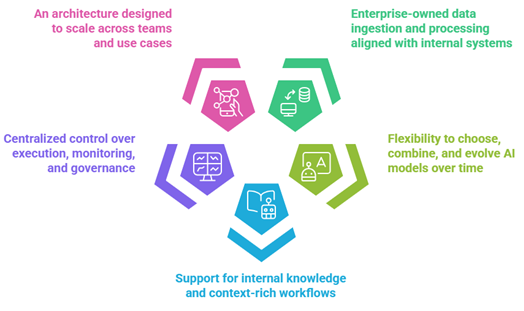
- Enterprise-owned data ingestion and processing aligned with internal systems
- Flexibility to choose, combine, and evolve AI models over time
- Support for internal knowledge and context-rich workflows
- Centralized control over execution, monitoring, and governance
- An architecture designed to scale across teams and use cases
Together, these elements allow enterprises to build AI pipelines that are dependable, adaptable, and designed to grow alongside business needs.
Public AI Pipelines vs. private AI pipelines: Enterprise Trade-Offs Explained
As enterprises evaluate how to operationalize AI, many consider pipelines built on public AI services alongside internally managed approaches. Both models enable access to advanced AI capabilities, but they differ in how data, models, and control are handled as AI usage grows across teams and systems. Understanding these trade-offs helps leaders align AI initiatives with long-term architectural and operational goals.
| Public AI Pipelines | Private AI Pipelines |
| AI accessed through external APIs | AI pipelines operate within enterprise-controlled environments |
| Data sent to third-party services | Data remains within defined enterprise boundaries |
| Usage-based pricing tied to volume | More predictable cost models aligned with internal usage |
| Limited visibility into model lifecycle | Greater control over model lifecycle management |
| Standardized workflows across customers | Support for proprietary data workflows |
| Governance handled externally | Built to support enterprise AI control and internal policies |
From an enterprise perspective, the distinction is not about capability, but about alignment. Private AI pipelines are often chosen when organizations want AI initiatives to reflect how their data, systems, and governance structures already operate. This approach makes it easier to integrate AI into existing workflows, manage change over time, and support AI as a long-term capability rather than a standalone service.
GenE: The Orchestration Layer to Build Your Own private AI pipelines
Building private AI pipelines requires more than access to data and models. It requires an orchestration layer that can coordinate how data flows, how models are applied, and how outcomes are delivered across enterprise systems. This is the role GenE is designed to play.
GenE operates as an AI orchestration and automation layer that sits between enterprise data sources and AI models. It enables organizations to connect their own data with their preferred models, while maintaining consistency, control, and governance across the pipeline.
By acting as an orchestration layer rather than a model provider, GenE allows enterprises to design private AI pipelines that align with their existing architecture. Data remains within enterprise boundaries, models can be selected and evolved over time, and AI workflows can be managed as part of the broader technology stack rather than as isolated implementations.
How GenE Builds private AI pipelines Using Your Data and Your Models
A private AI pipeline built with GenE follows a clear and repeatable structure. Each stage is designed to align with enterprise systems, governance requirements, and long-term operational needs, while allowing flexibility in how data and models are used.
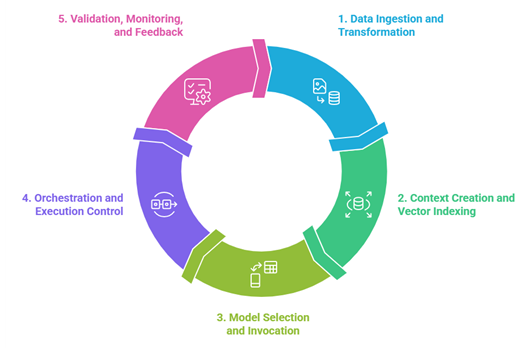
- Data ingestion and transformation
Enterprise data is brought into the pipeline from internal sources such as databases, documents, and operational systems. This step focuses on data ingestion and transformation, ensuring data is structured, contextualized, and ready for downstream AI use without altering source systems.
- Context creation and vector indexing
Relevant data is indexed to support efficient retrieval. Through vector DB indexing, enterprise knowledge is made accessible to AI models in a way that supports accuracy and real-time responsiveness while preserving internal data boundaries.
- Model selection and invocation
GenE enables enterprises to apply their preferred models commercial, open-source, or internal at the appropriate stage of the pipeline. This supports ongoing model lifecycle management, allowing models to be evaluated, updated, or replaced without redesigning the pipeline.
- Orchestration and execution control
As requests move through the pipeline, GenE coordinates how each step is executed. This orchestration layer ensures that logic, sequencing, and decision points remain consistent across workflows, supporting enterprise AI control as usage scales.
- Validation, monitoring, and feedback
Outputs are validated before being delivered to downstream systems or users. Monitoring and feedback loops support real-time pipelines, enabling continuous refinement while maintaining operational oversight.
Through this approach, GenE enables enterprises to build private AI pipelines that integrate cleanly with existing systems, respect data ownership, and remain adaptable as business and technology requirements evolve.
A Private AI Pipeline in Practice: From Enterprise Data to Decisions
Consider an enterprise operations team responsible for monitoring day-to-day performance across multiple systems. Data is spread across internal reports, operational databases, documents, and dashboards. The goal is to provide timely insights to decision-makers without exposing data externally or creating new operational overhead.
Using private AI pipelines built with GenE, the organization connects its internal data sources into a governed pipeline. Through structured data ingestion and transformation, operational data and documents are prepared for AI use while remaining within enterprise-controlled environments. Knowledge is indexed to support fast retrieval, enabling teams to query current and historical information as part of their daily workflows.
When questions arise, AI models are invoked through the pipeline to analyze trends, summarize performance, or surface exceptions. Because the pipeline supports enterprise-selected models, teams retain flexibility in model lifecycle management while ensuring outputs reflect internal context. Orchestration ensures that responses are delivered consistently and aligned with internal policies.
Over time, this approach enables real-time pipelines that support ongoing decision-making. Insights are delivered directly into existing tools and processes, reducing manual effort and improving responsiveness. By keeping data, models, and execution under enterprise control, the organization uses AI as a dependable operational capability rather than a standalone tool.
Enterprise-Wide Benefits of private AI pipelines
As private AI pipelines are adopted across teams and functions, their impact extends beyond individual use cases. What begins as a way to manage data and models more deliberately becomes a foundation for how AI is governed, scaled, and sustained across the enterprise.
At an organizational level, this approach enables several consistent benefits:
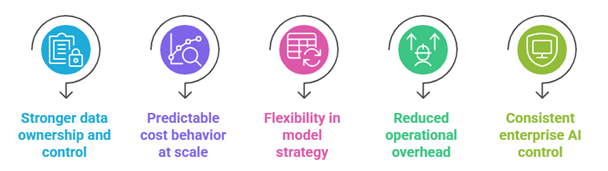
- Stronger data ownership and control
By keeping data within defined boundaries, enterprises support data sovereignty and ensure AI initiatives align with internal policies and regulatory expectations.
- Predictable cost behavior at scale
Compared to usage-based public services, private AI pipelines support more stable cost planning, helping leaders balance predictive cost vs usage fees as AI adoption grows.
- Flexibility in model strategy
Enterprises can evolve models over time through structured model lifecycle management, without redesigning pipelines or disrupting downstream workflows.
- Reduced operational overhead
Centralized orchestration and monitoring simplify AI operations, lowering operational overhead as more teams and workflows adopt AI.
- Consistent enterprise AI control
With execution paths, validation, and governance managed centrally, organizations maintain enterprise AI control while allowing teams to innovate within clear boundaries.
Taken together, these benefits help position AI as a long-term enterprise capability. Instead of managing isolated implementations, leaders gain a cohesive way to deploy, operate, and evolve AI initiatives in alignment with business and technology strategy.
Conclusion
As AI becomes part of everyday enterprise operations, the way AI systems are built matters as much as the outcomes they produce. Pipelines designed around enterprise-owned data, model flexibility, and architectural control allow organizations to align AI initiatives with long-term technology and governance goals.
By adopting private AI pipelines, enterprises create a foundation where AI can evolve alongside business needs. Data remains within defined boundaries, models can be selected and updated deliberately, and execution is integrated into existing systems rather than operating in isolation. This approach allows AI to move from experimentation to dependable infrastructure.
If you are exploring how to build AI pipelines that fit your data, systems, and long-term requirements, GenE is designed to support that journey. GenE enables enterprises to create production-ready private AI pipelines that are governed, adaptable, and aligned with how enterprise platforms operate today.
FAQs
What are private AI pipelines?
Private AI pipelines are AI pipelines designed to operate within enterprise-controlled environments. They ingest internal data, apply selected AI models, and deliver outcomes through governed execution paths that align with enterprise systems and policies.
How are private AI pipelines different from public AI pipelines?
Public AI pipelines rely on external services and usage-based access. Private AI pipelines provide greater control over data movement, model selection, and execution, supporting enterprise governance and predictable operations.
Can enterprises use their own models with private AI pipelines?
Yes. Private AI pipelines are designed to support enterprise-selected models, including commercial, open-source, and internal models, with structured model lifecycle management.
How do private AI pipelines support compliance and governance?
By keeping data and execution within enterprise boundaries, private AI pipelines support compliance-driven architecture. Validation, monitoring, and control mechanisms are applied consistently across workflows.
Are private AI pipelines suitable for real-time use cases?
Yes. With appropriate orchestration and monitoring, private AI pipelines can support real-time pipelines for analytics, decision support, and process automation.
When should an enterprise consider moving to private AI pipelines?
Enterprises often consider private AI pipelines as AI usage expands across teams, systems, and workflows, and when long-term control over data, cost, and model strategy becomes a priority.